MLCommons Releases New MLPerf Inference v5.1 Benchmark Results
New results highlight AI industry’s latest technical advances
SAN FRANCISCO, Sept. 09, 2025 (GLOBE NEWSWIRE) -- Today, MLCommons® announced new results for its industry-standard MLPerf® Inference v5.1 benchmark suite, tracking the relentless forward momentum of the AI community and its new capabilities, new models, and new hardware and software systems.
The MLPerf Inference benchmark suite is designed to measure how quickly systems can run AI models across a variety of workloads. The open-source and peer-reviewed suite performs system performance benchmarking in an architecture-neutral, representative, and reproducible manner, creating a level playing field for competition that drives innovation, performance, and energy efficiency for the entire industry. It provides critical technical information for customers who are procuring and tuning AI systems.
This round of MLPerf Inference results sets a record for the number of participants submitting systems for benchmarking at 27. Those submissions include systems using five newly-available processors and improved versions of AI software frameworks. The v5.1 suite introduces three new benchmarks that further challenge AI systems to perform at their peak against modern workloads.
"The pace of innovation in AI is breathtaking," said Scott Wasson, Director of Product Management at MLCommons. "The MLPerf Inference working group has aggressively built new benchmarks to keep pace with this progress. As a result, Inference 5.1 features several new benchmark tests, including DeepSeek-R1 with reasoning, and interactive scenarios with tighter latency requirements for some LLM-based tests. Meanwhile, the submitters to MLPerf Inference 5.1 yet again have produced results demonstrating substantial performance gains over prior rounds."
Llama 2 70B generative AI test establishes the trendlines
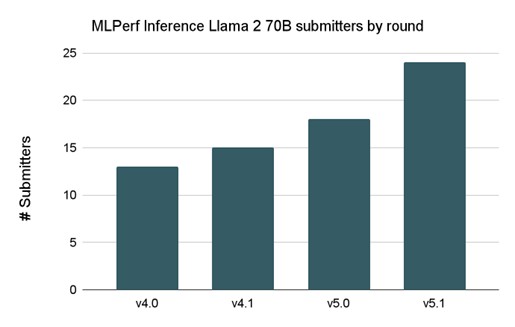
The Llama 2 70B benchmark continues to be the most popular benchmark in the suite, with 24 submitters in this round.
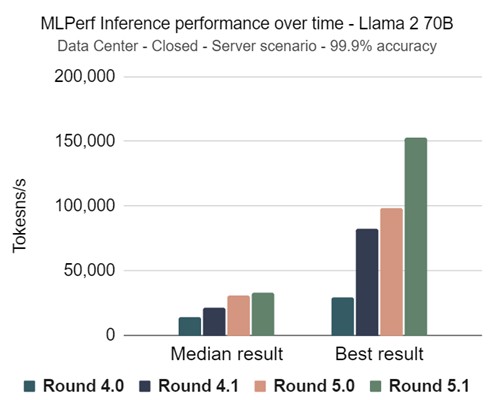
It also gives a clear picture of overall performance improvement in AI systems over time. In some scenarios, the best performing systems improved by as much as 50% over the best system in the 5.0 release just six months ago. This round saw another first: a submission of a heterogeneous system that used software to load-balance an inference workload across different types of accelerators.
In response to demand from the community, this round expands the interactive scenario introduced in the previous version, which tests performance under lower latency constraints as required for agentic and other applications of LLMs. The interactive scenarios, now tested for multiple models, saw robust participation from submitters in version 5.1.
Three new tests introduced
MLPerf Inference v5.1 introduces three new benchmarks to the suite: DeepSeek-R1; Llama 3.1 8B; and Whisper Large V3.
DeepSeek R1 is the first “reasoning model” to be added to the suite. Reasoning models are designed to tackle challenging tasks, using a multi-step process to break down problems into smaller pieces in order to produce higher quality responses. The workload in the test incorporates prompts from five datasets covering mathematics problem-solving, general question answering, and code generation.
“Reasoning models are an emerging and important area for AI models, with their own unique pattern of processing,” said Miro Hodak, MLPerf Inference working group co-chair. “It’s important to have real data to understand how reasoning models perform on existing and new systems, and MLCommons is stepping up to provide that data. And it’s equally important to thoroughly stress-test the current systems so that we learn their limits; DeepSeek R1 increases the difficulty level of the benchmark suite, giving us new and valuable information.”
More information on the DeepSeek R1 benchmark can be found here.
Llama 3.1 8B is a smaller LLM useful for tasks such as text summarization in both datacenter and edge scenarios. With the Inference 5.1 release, this model is replacing an older one (GPT-J) but retaining the same dataset, performing the same benchmark task but with a more contemporary model that better reflects the current state of the art. Llama 3.1 8B uses a large context length of 128,000 tokens, whereas GPT-J only used 2048. The test uses the CNN-DailyMail dataset, among the most popular publicly available for text summarization tasks. The Llama 3.1 8B benchmark supports both datacenter and edge systems, with custom workloads for each.
More information on the Llama 3.1 8B benchmark can be found here.
Whisper Large V3 is an open-source speech recognition model built on a transformer-based encoder-decoder architecture. It features high accuracy and multilingual capabilities across a wide range of tasks, including transcription and translation. For the benchmark test it is paired with a modified version of the Librispeech audio dataset. The benchmark supports both datacenter and edge systems.
“MLPerf Inference benchmarks are live and designed to capture the state of AI deployment across the industry,” said Frank Han, co-chair of the MLPerf Inference Working Group. “This round adds a speech-to-text model, reflecting the need to benchmark beyond large language models. Speech recognition combines language modeling with additional stages like acoustic feature extraction and segmentation, broadening the performance profile and stressing system aspects such as memory bandwidth, latency, and throughput. By including such workloads, MLPerf Inference offers a more holistic and realistic view of AI inference challenges.”
More information on the Whisper Large V3 benchmark can be found here.
The momentum builds for AI… and for MLPerf benchmarks
The MLPerf Inference 5.1 benchmark received submissions from a total of 27 participating organizations: AMD, ASUSTek, Azure, Broadcom, Cisco, Coreweave, Dell, GATEOverflow, GigaComputing, Google, Hewlett Packard Enterprise, Intel, KRAI, Lambda, Lenovo, MangoBoost, MiTac, Nebius, NVIDIA, Oracle, Quanta Cloud Technology, Red Hat Inc, Single Submitter: Amitash Nanda, Supermicro, TheStage AI, University of Florida, and Vultr.
The results included tests for five newly-available accelerators:
- AMD Instinct MI355X
- Intel Arc Pro B60 48GB Turbo
- NVIDIA GB300
- NVIDIA RTX 4000 Ada-PCIe-20GB
- NVIDIA RTX Pro 6000 Blackwell Server Edition
“This is such an exciting time to be working in the AI community,” said David Kanter, head of MLPerf at MLCommons. “Between the breathtaking pace of innovation and the robust flow of new entrants, stakeholders who are procuring systems have more choices than ever. Our mission with the MLPerf Inference benchmark is to help them make well-informed choices, using trustworthy, relevant performance data for the workloads they care about the most. The field of AI is certainly a moving target, but that makes our work – and our effort to stay on the cutting edge – even more essential.”
Kanter continued, “We would like to welcome our new submitters for version 5.1: MiTac, Nebius, Single Submitter: Amitash Nanda, TheStage AI, University of Florida, and Vultr. And I would particularly like to highlight our two participants from academia: Amitash Nanda, and the team from the University of Florida. Both academia and industry have important roles to play in efforts such as ours to advance open, transparent, trustworthy benchmarks. In this round we also received two power submissions, a data center submission from Lenovo and an edge submission from GATEOverflow. MLPerf Power results combine performance results with power measurements to offer a true indication of power-efficient computing. We commend these participants for their submissions and invite broader MLPerf Power participation from the community going forward.”
View the results
To view the results for MLPerf Inference v5.1, please visit the Datacenter and Edge benchmark results pages.
About MLCommons
MLCommons is the world’s leader in AI benchmarking. An open engineering consortium supported by over 125 members and affiliates, MLCommons has a proven record of bringing together academia, industry, and civil society to measure and improve AI. The foundation for MLCommons began with the MLPerf benchmarks in 2018, which rapidly scaled as a set of industry metrics to measure machine learning performance and promote transparency of machine learning techniques. Since then, MLCommons has continued to use collective engineering to build the benchmarks and metrics required for better AI – ultimately helping to evaluate and improve the accuracy, safety, speed, and efficiency of AI technologies.
For additional information on MLCommons and details on becoming a member, please visit MLCommons.org or email participation@mlcommons.org.
Press Inquiries: contact press@mlcommons.org
Photos accompanying this announcement are available at
https://www.globenewswire.com/NewsRoom/AttachmentNg/e7e63ecd-ed99-4ceb-bfe2-847abc32d2e6
https://www.globenewswire.com/NewsRoom/AttachmentNg/1057c0ca-e973-409d-9969-42f725cc70d9

![]()
MLPerf Inference Llama 2 70B submitters by round
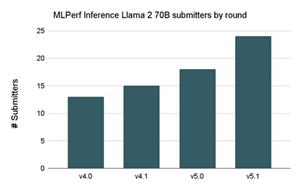
MLPerf Inference submitters increased significantly for Llama 2 70B in v5.1
MLPerf Inference performance over time - Llama 2 70B
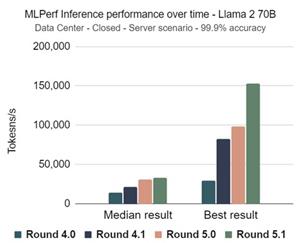
Data center - closed - server scenario - 99.9% accuracy
Legal Disclaimer:
EIN Presswire provides this news content "as is" without warranty of any kind. We do not accept any responsibility or liability for the accuracy, content, images, videos, licenses, completeness, legality, or reliability of the information contained in this article. If you have any complaints or copyright issues related to this article, kindly contact the author above.
